
Triangulate
The Triangulation step uses the matches found in the previous step and finds
- The 3D location of matches
- The 3D location of the cameras (i.e. where the pictures have been shot, also called extrinsic parameters)
- The intrinsic parameters of the camera (zoom setting, distortion and others)
To start this step, click on the "Matching" item in the project tree and select "Triangulation...". The following dialog appears:
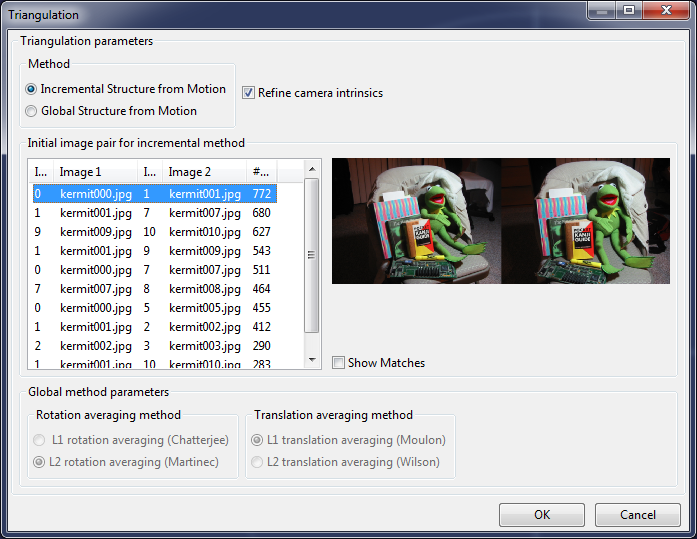
Regard3D offers two algorithms for structure-from-motion (triangulation):
- Incremental: It starts off with the selected image pair and tries adding other images. Each step will perform a bundle adjustment to determine the camera parameters and the 3D positions of the keypoints ("tracks")
- Global: This engine tries to find the camera parameters and 3D positions of the keypoints globally by using all images in one step. In the current version, this engine is only available if all pictures are taken from the same camera and with the same zoom setting ("focal length").
The global engine is usually faster, but requires more matches for good results. The incremental engine however has the drawback that a good starting pair must be selected manually. Please use the following criteria for finding a good starting pair:
- High amount of matches
- Wide baseline (the positions where the images were taken should not be too close)
For the global engine, you have the following choices:
- L1 rotation averaging (Chatterjee): This implements a scheme described in the paper "Efficient and Robust Large-Scale Rotation Averaging" by Avishek Chatterjee and Venu Madhav Govindu, ICCV 2013
- L2 rotation averaging (Martinec): Implementation of the paper "Robust Multiview Reconstruction" by Daniel Martinec, 2008
- L1 translation averaging (Moulon): Implementation of the paper "Global Fusion of Relative Motions for Robust, Accurate and Scalable Structure from Motion" by Pierre Moulon, Pascal Monasse and Renaud Marlet. In ICCV, 2013
- L2 translation averaging (Wilson): Implementation of the paper "Robust Global Translations with 1DSfM" by Kyle Wilson and Noah Snavely, ECCV 2014. See also this page: Robust Global Translations with 1DSfM
All those implementations are part of OpenMVG.
The check box "Refine camera intrinsics" should be left on (checked). In the future, it is planned that known camera intrinsics can be set before triangulation. In this case, it will make sense to keep the camera intrinsics fixed. But for now, keep this box checked.
After clicking "OK" the selected engine will run. When it is finished, a dialog will show the results. The most important figures are "Cameras calibrated/total". For example, if it says "11/11", all cameras have been calibrated, i.e. the 3D positions and parameters of all pictures have been found. If not all cameras have been calibrated, you can try again using a different method or different starting pair.
The triangulated keypoints ("tracks") and the cameras are now displayed in the 3D view. To improve visibility, increase the point size with the slider on the top right.
If the triangulation step fails, Regard3D will report an error. For details, please see the console window. To open the console window, use the menu item View -> Console output. The most frequent problem is that there are too few matches. Please try to increase the keypoint sensitivity and/or keypoint matching ratio.
Go to next article: Densification